








2026具身数据开源潮,核心数据集开放情况梳理(excel版)

数据集开源不是终点,如何让这些数据真正转化为技术成果,如何建立统一的数据标准,才是接下来要解决的问题。
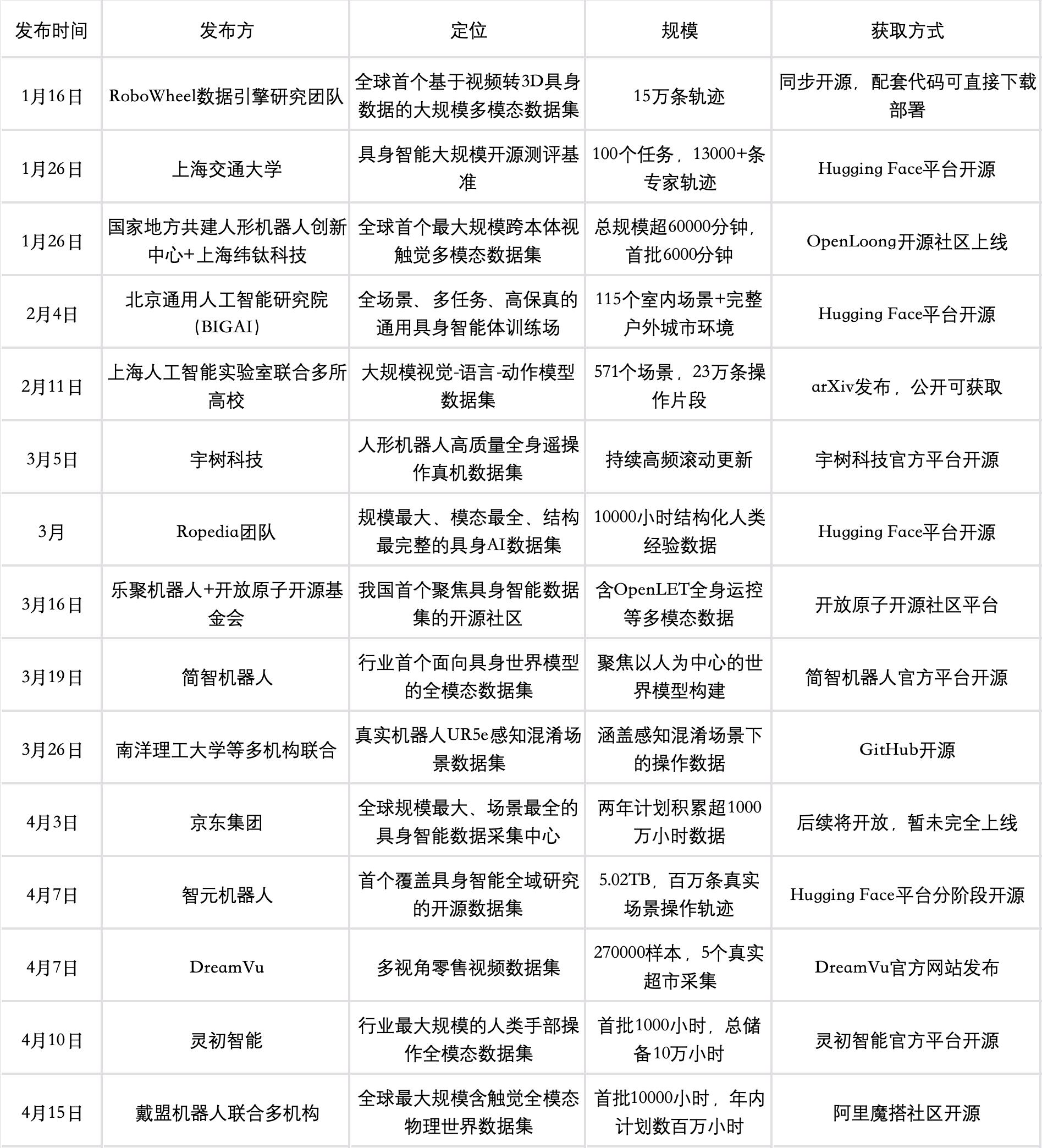
2026年AI圈的最大惊喜,来自具身智能的数据开源。
从1月上海交大的GM-100测评集,到4月戴盟联合谷歌DeepMind推出的全球最大触觉数据集,短短四个月,十几家企业、机构密集开放核心数据,这波操作直接助推AI和具身智能行业的发展节奏。

行业数据显示,具身智能需要数百PB级物理交互数据,当前存量缺口超90%,再加上采集成本高到离谱,一套真机操作数据集动辄上千万投入,很多企业只能困在实验室里。
这波开源潮,众多具身智能公司参与其中。
戴盟开放的Daimon-Infinity数据集,首批就有10000小时含触觉的全模态数据,覆盖80多个场景,解决了触觉数据稀缺的难题,用它预训练模型,训练效率能提升10倍。智元的AGIBOT WORLD 2026数据集,5.02TB全是真实场景采集,让机器人不用再靠仿真数据“纸上谈兵”。
合成数据已被证明不能完全满足厂商训练,泛化能力差,放到真实场景就“失灵”。现在有了真实场景的多模态数据,AI能更快理解物理世界,不管是机器人精细操作,还是视觉-语言交互,都能实现质的提升。同时,更多的开源数据,让众多厂商省去了数据采集的成本,能把钱花在模型优化上,行业竞争也从“数据垄断”转向“技术比拼”。
市场反应来得比想象中更快,百度、京东赶在4月先后上线数据交易平台,百度的数据超市适配主流开源模型,京东的平台则打通了数据采集到落地的全链路,首批就开放2000小时高精标注数据。
市场的热情背后,更多是行业对突破瓶颈的迫切需求。数据集开源不是终点,如何让这些数据真正转化为技术成果,如何建立统一的数据标准,才是接下来要解决的问题。
目前来看,开源潮还在继续,行业的竞争也从硬件转向数据。至于最终能催生出多少成熟应用,还需要时间来检验,毕竟技术落地从来都不是一蹴而就的事。









评论 0